Agent Queue¶
A self-improving orchestration platform for AI coding agents.
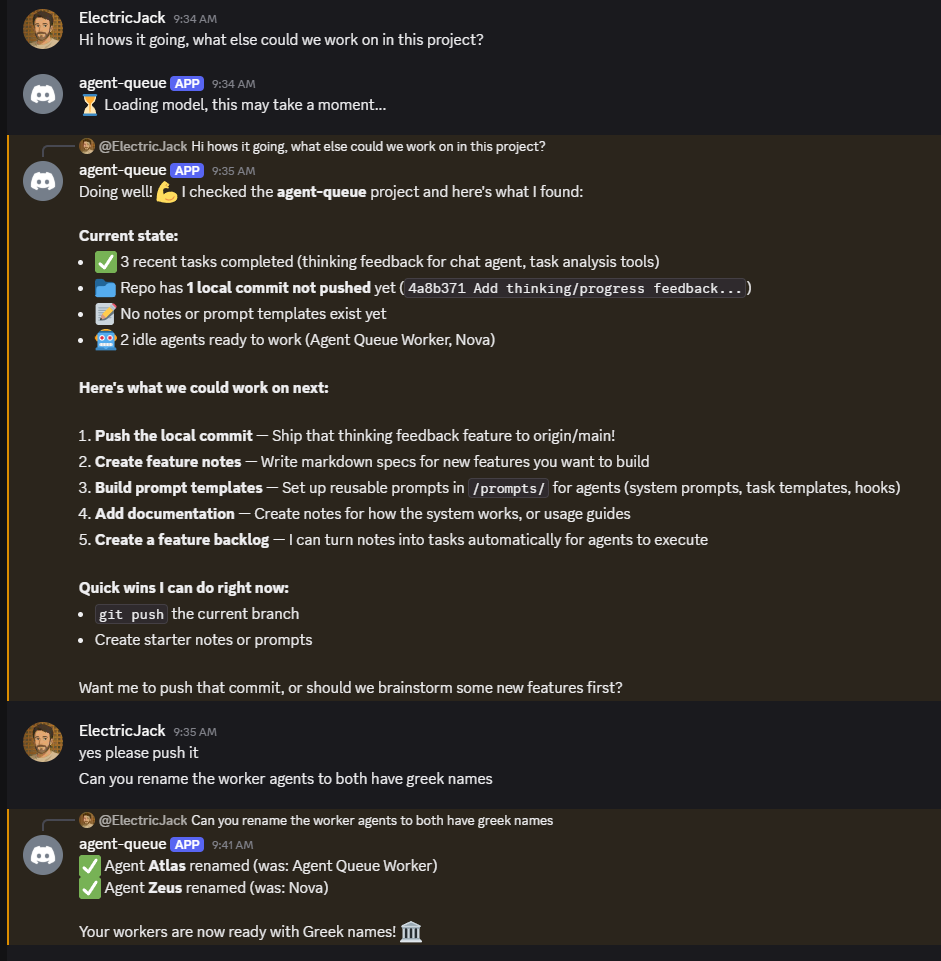
Agent Queue manages task queues across multiple projects, coordinates multi-agent workflows through executable playbooks, accumulates knowledge via a 4-tier memory architecture, and continuously improves through automated reflection. Every completed task feeds insights back into the system — the longer it runs, the better it gets.
You manage everything from Discord on your phone, your terminal, or any MCP-compatible client. Queue up a week's worth of tasks before you leave the house. Come back to a stack of completed PRs and a system that knows more about your codebase than it did yesterday.
 |
 |
How it works¶
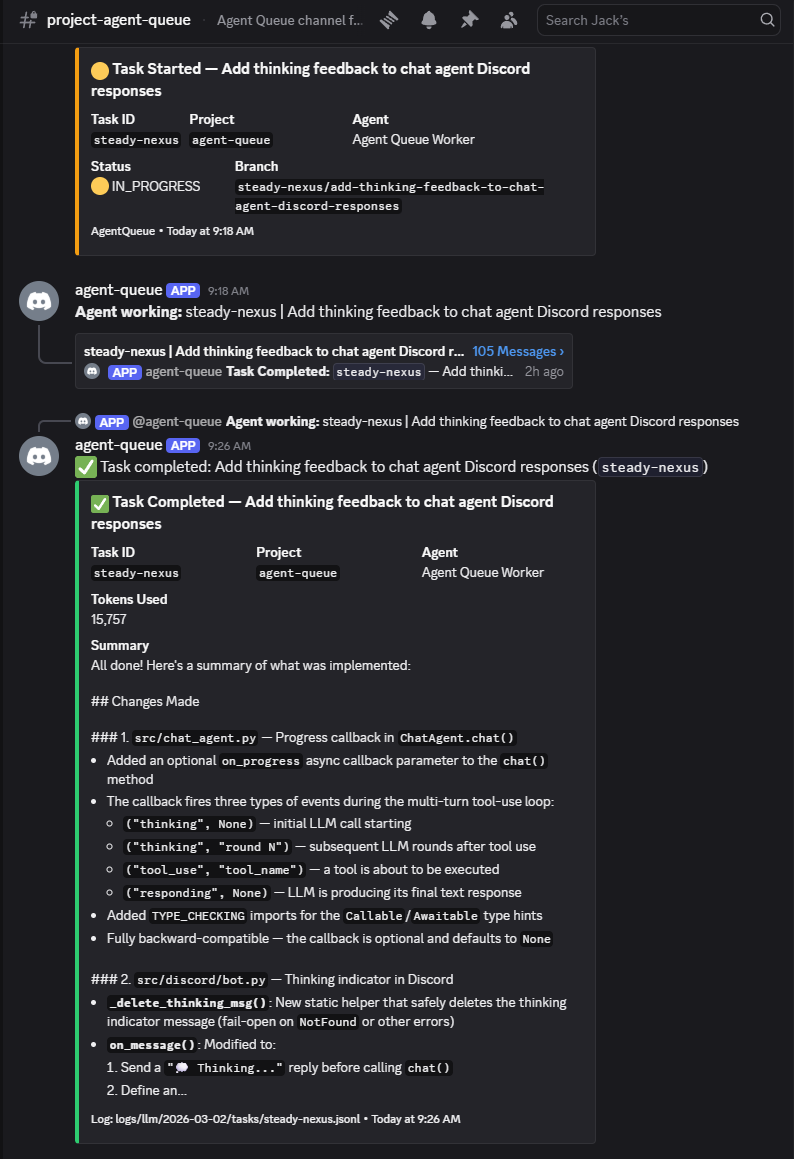
Agent Queue runs as a background daemon. You talk to it through Discord, the CLI, or an MCP client. A Supervisor (LLM-powered conversation interface) understands context, remembers what you were working on, and acts. Behind the scenes, a deterministic Orchestrator manages the task lifecycle — scheduling, dependencies, retries — without spending a single LLM token.
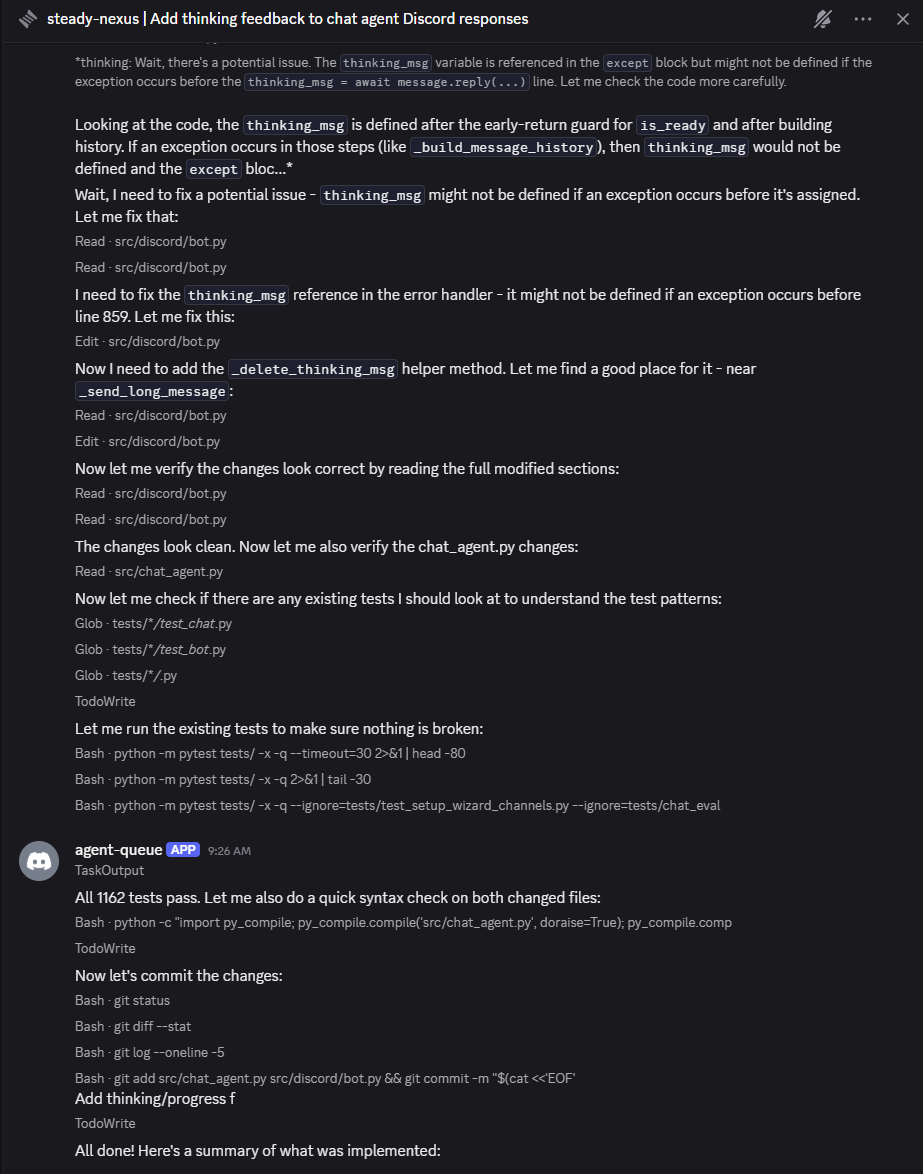
What makes it different: the system learns from every task. A reflection engine reviews completed work, extracts generalizable insights, and writes them to scoped memory. Future agents receive those insights through a 4-tier prompt assembly pipeline. Playbooks automate multi-step workflows — from code quality gates to full feature development pipelines with review cycles. The system gets measurably better the longer it runs.
Features¶
Self-Improvement¶
- Reflection engine. Post-task review extracts what worked, what failed, and what to remember. Deep/standard/light tiers with circuit breaker protection to control token spend.
- Continuous learning. Error patterns, successful strategies, and project conventions accumulate in scoped memory — system, agent-type, and project levels.
- Knowledge consolidation. Periodic playbooks distill raw task memories into structured knowledge bases, project factsheets, and cross-project wisdom.
- Autonomous operation. No manual intervention needed. Reflection playbooks run automatically, write insights, and feed them to future agents.
Orchestration¶
- Parallel agents. Multiple Claude Code agents work simultaneously across projects, each in its own workspace with your existing environment (
.env,venv,node_modules). - Full task lifecycle. Created → assigned → branched → worked → tested → completed. Retries on failure, escalates when stuck, never silently drops work.
- Live streaming. Each task gets a Discord thread. Watch agents work in real time. Reply to unblock them.
- Rate limit recovery. When an agent hits the throttle, the task auto-pauses. When the window resets, it auto-resumes. While one agent is throttled, others keep working.
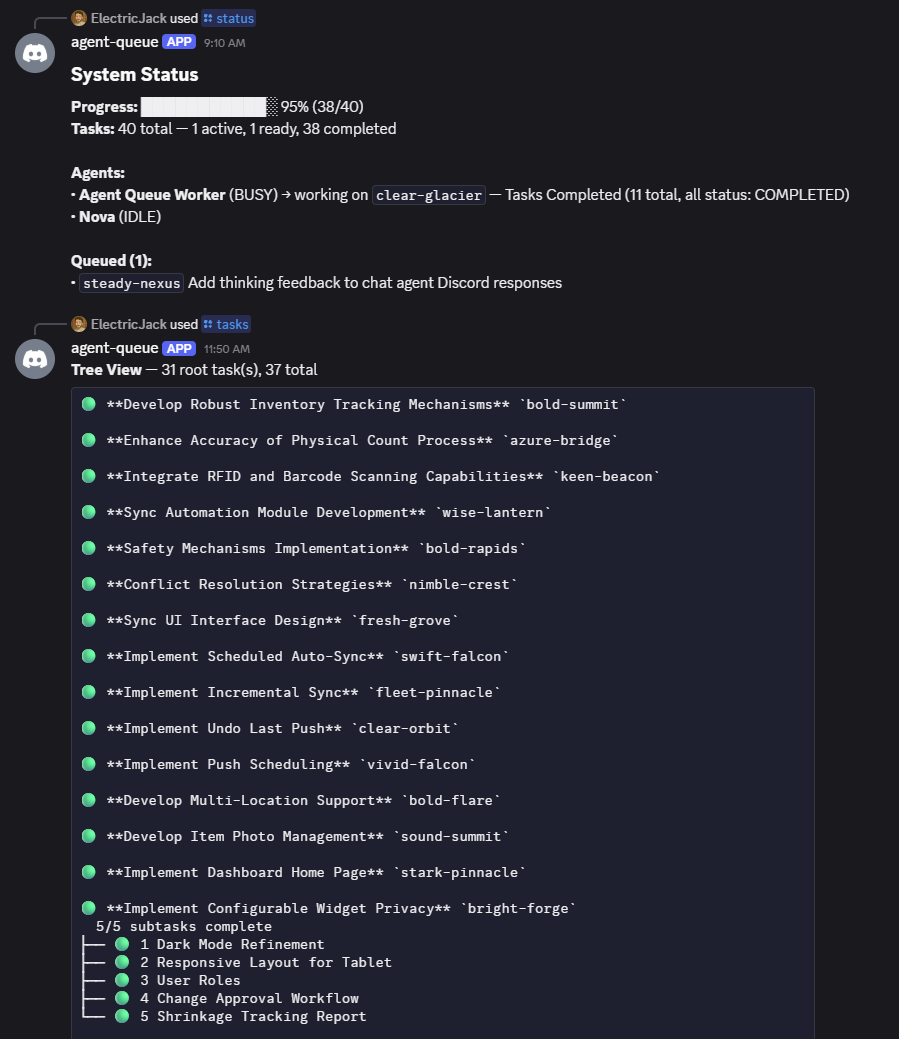
- Proportional scheduling. Weight projects by priority. The deficit-based scheduler distributes work fairly across a rolling window — all deterministic, zero LLM overhead.
Playbooks — Workflow Automation¶
- Multi-step workflows. Author automation as markdown files. An LLM compiles them into executable directed graphs with conditional branching and accumulated context.
- Event-driven triggers. Playbooks fire on system events (
task.completed,git.push,timer.24h) and compose via event chaining. - Human-in-the-loop. Pause execution at checkpoints for review. Resume with human input that flows into the conversation context.
- Scoped automation. System-wide, project-specific, or agent-type playbooks — each runs only where it applies.
- Built-in pipelines. Feature development (code → review → QA), bugfix (code → QA), parallel exploration (multiple agents investigate different approaches), and code quality gates ship as default playbooks.
Agent Coordination¶
- Playbook-driven workflows. Multi-agent pipelines defined as readable markdown — feature development, review cycles, parallel exploration, exclusive-access migrations.
- Agent affinity. Prefer agents with context continuity from earlier workflow stages. Advisory with bounded wait — falls back when the preferred agent is busy.
- Workspace strategies. Exclusive locks (default, safe), branch-isolated (parallel work on same repo), directory-isolated (monorepo support).
- Temporary constraints. Exclusive project access for migrations, per-type concurrency limits, coordinator-scheduler separation of concerns.
Memory & Knowledge¶
- 4-tier memory. Identity (L0), Critical Facts (L1), Topic Context (L2), Deep Search (L3) — the right knowledge loaded at the right time.
- Semantic search + KV store + temporal facts. Milvus-backed unified storage supporting vector search, exact lookups, and time-windowed facts with full history.
- Reflection engine. Post-task review extracts insights and feeds them back to future agents. Deep/standard/light tiers with circuit breaker protection.
- Knowledge consolidation. Daily extraction of facts from task outcomes. Weekly deep consolidation organizes them into structured knowledge bases.
- Scoped knowledge. System → Agent-Type → Project hierarchy. Knowledge flows from broad to specific. Automatic deduplication and LLM-powered merging.
Extensibility¶
- Plugin system. 5 internal plugins ship by default. Install third-party plugins from git repos. Plugins register tools, events, cron jobs, CLI commands, and Discord slash commands.
- Agent profiles. Configure agent behavior, tools, and MCP servers via markdown profiles. Assign per-project or per-task.
- MCP server. ~150 tools auto-exposed via Model Context Protocol. Connect from Claude Code, Cursor, or any MCP client.
- Multi-provider. Anthropic direct, AWS Bedrock, Google Vertex AI, Gemini, or Ollama.
Operations¶
- Token tracking. Per-project and per-task usage breakdowns. Fair-share budgets. Daily playbook token caps.
- Crash recovery. SQLite-backed state. Survives restarts. Dead agents detected, tasks rescheduled, timers resumed.
- Vault & Obsidian. All knowledge, playbooks, and profiles stored as markdown in
~/.agent-queue/vault/. Browse with Obsidian, edit with any text editor. - Zero orchestration overhead. No LLM calls for scheduling. Every token goes to agent work.
- Memory health. Collection sizes, retrieval hit rates, stale memory detection, growth rate tracking — verify the learning loop is working.
Why Agent Queue?¶
- Self-improving. The system gets better with use. Reflection extracts insights, memory preserves them, playbooks act on them. Not just a task runner — a learning system.
- Structure guides intelligence. Playbooks encode process knowledge (what to do, in what order, with what context). Agents provide judgment within those processes. Flexible enough for novel situations, defined enough to debug.
- Transparent. Everything is markdown files in a vault. Nothing is hidden in opaque databases or API calls. Browse with Obsidian, edit with vim, diff with git.
- Development-specific. Git branches, test verification, merge conflict handling, workspace isolation, code quality gates. Built for software development, not calendar automation.
- Lightweight. One Python process, SQLite. Runs on a Raspberry Pi. No Redis, no Kubernetes. PostgreSQL supported for production deployments.
- You're in control. Nothing merges, nothing deploys without you seeing it. Discord notifications keep you in the loop from your phone.
Getting started¶
Prerequisites¶
- Python 3.12+
- A Discord bot token (create one here)
- Claude Code installed and configured
Install & setup¶
The setup script installs dependencies, creates the vault structure, and walks you through Discord configuration, API keys, and getting your first agent running.
To uninstall, run ./uninstall.sh from the repo root. It returns the repo to a fresh-clone state (git reset --hard + git clean -ffdx) and prompts before removing the ~/.agent-queue/ config directory. Pass -y to skip prompts; --keep-user-dir to preserve ~/.agent-queue/.
First steps¶
Once the bot is online, everything happens through conversation in your control channel:
You: link ~/code/my-app as my-app
Bot: ✓ Linked. Repo "my-app" registered.
You: create a project called my-app
Bot: ✓ Project my-app created.
You: create agent claude-1 and assign it to my-app
Bot: ✓ Agent claude-1 created.
You: add a task to add rate limiting to the API
Bot: Created task `task-1` — "Add rate limiting to API"
Assigned to claude-1. I'll post updates in the thread.
Or use the CLI:
aq status # system overview
aq task add "Add rate limiting" -p my-app # create a task
aq task list # see all tasks
Or connect via MCP from Claude Code, Cursor, or any MCP-compatible client for programmatic access to ~150 tools.
Next steps¶
Guides:
- [[guides/getting-started|Getting Started]] — Installation and setup
- [[guides/discord-commands|Discord Commands]] — Slash commands and chat interactions
- [[guides/architecture|Architecture]] — How the system is designed
- [[guides/cli|CLI]] — Terminal interface reference
- [[guides/agent-tools|Agent Tools]] — Tool reference for AI agents
- [[guides/platform-development|Platform Development]] — Adding new agent backends
- dashboard/CLAUDE.md (in-repo) — Typed @aq/ts-client workflow for the React dashboard
Specifications: - [[specs/design/README|Design Specs]] — Guiding principles, playbooks, memory, self-improvement, coordination - [[specs/orchestrator|Orchestrator]] — Core task and agent lifecycle - [[specs/supervisor|Supervisor]] — LLM conversation loop and reflection - [[specs/models-and-state-machine|Models & State Machine]] — Task lifecycle states
License¶
MIT